About
Kun has more than 6 years’ experience as a R&D Computer Vision Software Engineer in the automation industry.
He received Master degree of Computer Science from the Cooperative Graduate School System at University of Tsukuba and AIST. During the program, he studied computer vision, RGBD-SLAM, 3D reconstruction, deep learning, and 3D sensor calibration.
After graduation, Kun joined Toshiba, Mujin, and then Woven Planet Holdings. He has gained rich experiences in the automation and robotics industry. At Mujin, he was a Computer Vision Engineer focusing on object detection and 3D pose estimation. He is now a computer vision engineer working mapping technologies for autonomous driving and urban planning at Woven Planet Holdings.
During his leisure time, Kun takes a variety of online courses, continuously learning the latest cutting-edge technologies. He has gained experiences in machine learning, behavioral planning, and path planning, etc.
Work Highlights
Mapping
A Study on Automatic Selection of Key-frames for RGB-D SLAM


This work implemented a novel appraoch on how to select keyframes based on the distribution of matched inlier 2D keypoints to reduce the accumulated errors during continous estimation. See here for more technical details.
In this work, we exploit and analyze the distribution of matched 2D features to automatically determine the next keyframe to work with. This approach allows us to reduce the accumulated estimation error and also the number of data we need to store.
Automated Mapping Platform
Originally tweeted by Woven Planet Group (@WovenPlanet_JP) here.
Originally tweeted by Woven Planet Group (@WovenPlanet_JP) here.
Currently Kun is working on the Automated Mapping Platform project for Woven Planet Holdings. This project involves satellite imagery inference (space maps) and probe data aggregation (fusion maps). He has experience in both and right now is working on aerial feature extraction on the space maps side. Also he is working as a senior engineer leading the some of the technical discussion, composing coding standard, guiding code review and mentoring junior engineers.
6D Pose Estimation
6D Object Pose Estimation for Industrial Picking Robots
During the time when Kun was working for Mujin, he worked on the 6D pose estimations of target objects for piece-picking, palletizing, and de-palletizing robotics systems for warehouse and factory automation. His work has been deployed in many robot picking cells for customers, such as Paltac, Askul, Asone, Fast Retailing, etc.; see https://www.mujin.co.jp/videos/. These algorithms can handle a variety of objects, such as plastic containers, cardboard boxes, cages, pallets, cart racks, etc. Some the objects listed above is highly deformable and the approaches used should be flexible and meanwhile performant to meet the picking pace requirements by the projects.
Kun also optimized detectors’ algorithm and source code such that some of them can output poses within 80ms on a typical setup.
Object Detection & Classification
Traffic Sign Classifier

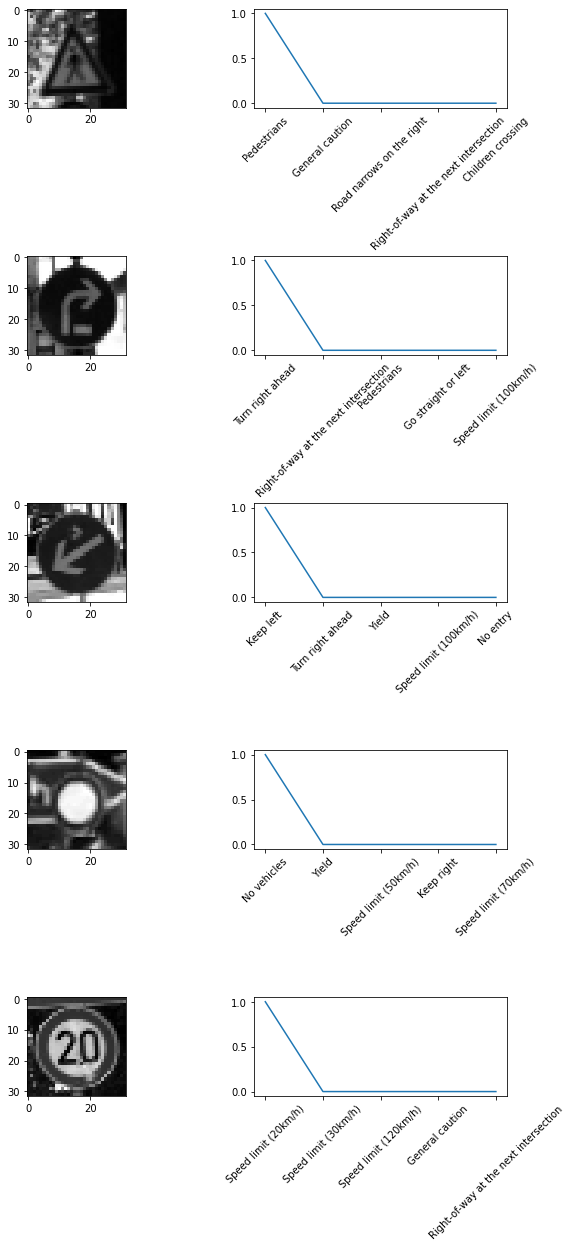
This work implements a traffic sign classifier for autonomous driving using a CNN model described in http://yann.lecun.com/exdb/publis/pdf/sermanet-ijcnn-11.pdf, the code is in https://github.com/kunlin596/TrafficSignClassifier. This work in done in pytorch. For more information about the approach and implementation detail, see https://github.com/kunlin596/TrafficSignClassifier/blob/master/writeup.md.
Image Captioning
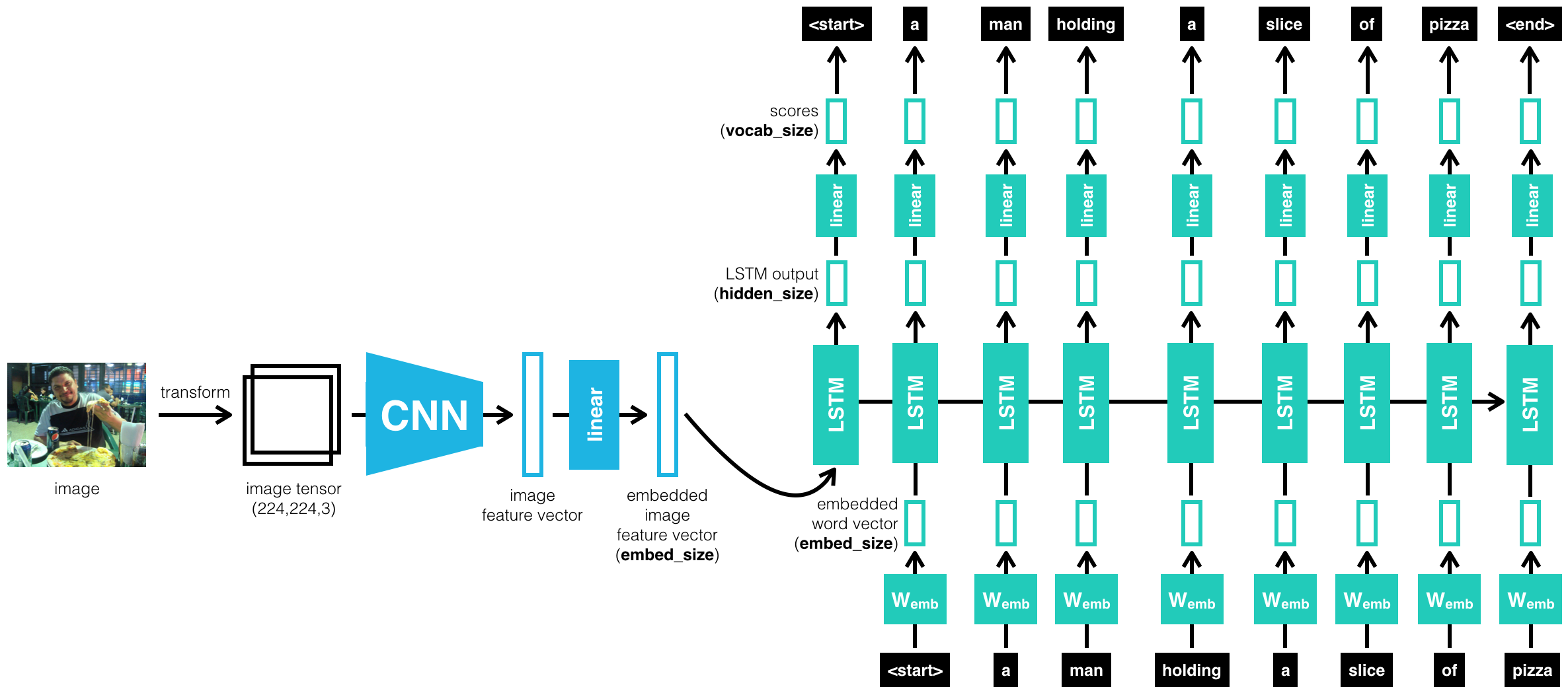
This work implements a image captioning framework using CNN for feature extraction, and RNN for captioning. The code is in https://github.com/kunlin596/image-captioning.
Facial Keypoints Detection
This work implements a facial keypoints detection for RGB images. By doing so, we can attach interesting objects such as sunglasses and beard to a face in an image. The code is in https://github.com/kunlin596/FacialKeypointsDetection.
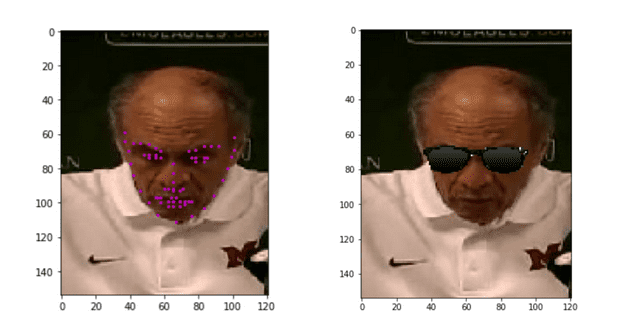
The training data and it’s attributes can be found in this notebook. Basically we need to annotate the facial keypoints as training data. The model architecture is based on LeNet apdapted CNN as described in this paper https://arxiv.org/pdf/1710.00977.pdf. The implementation detail can be found in this this notebook. The complete pipeline will include a frontal face detection as a prerequisite step. Here, a pretrained Haar detector is used for this purpose. The whole pipeline can be found in this notebook. The final execution result can be found in this notebook.
Planning
E2E Driving (Behavior Cloning)
This work implements the e2e driving described in https://images.nvidia.com/content/tegra/automotive/images/2016/solutions/pdf/end-to-end-dl-using-px.pdf. This is an interesting work since the it’s paper to demonstrate that an e2e network based on vision guided steering works. Note that the throttling is fixed in this simulation environement. The code is in https://github.com/kunlin596/BehavioralCloning. For more information about the approach and implementation, see https://github.com/kunlin596/BehavioralCloning/blob/master/writeup_report.md.
The idea is simple, we simply mount 3 cameras in the front of the vehicle, and record the image and the steering angle associated with the image tuple. Then we use CNN to do a regression learning associate particular image patterns to steering angles. During test, inputting 3 images from the camera, the model can predict the steering angle such that it drives based these images.



Highway Path Planning
This work implements a path planning algorithm described in Optimal Trajectory Generation for Dynamic Street Scenarios in a Frenet Frame described in https://www.researchgate.net/publication/224156269_Optimal_Trajectory_Generation_for_Dynamic_Street_Scenarios_in_a_Frenet_Frame. The code is in https://github.com/kunlin596/PathPlanning. More technical information about the approach and implementation, see https://github.com/kunlin596/PathPlanning/blob/master/writeup.pdf.
In the video, the green dots are the planned trajectory, every dot represents a waypoint, and the time interval is 0.02 seconds. Also note that in this simulation environement, we assume a perfect controller, where the vehicle can always reach the exact location as commanded in time.
The basic idea is to plan the trajectory not in the original XY plane, but on projected local Frenet frame. In this way, the planning problem can be reduced to a 1D problem. Then in the longitudinal and lateral direction, we can try to find a 6-order polynomial to compute a jerk minimzation trajectory. The resulting trajectory is smooth and elegant as in the video above.
Computer Graphics
Chess Using OpenGL and QtQuick5
This is a toy project for doing some experiments using OpenGL with QtQuick 5. The code is in https://github.com/kunlin596/tiny-chess-demo. It implements some basic animations and UI controls over the OpenGL canvas.